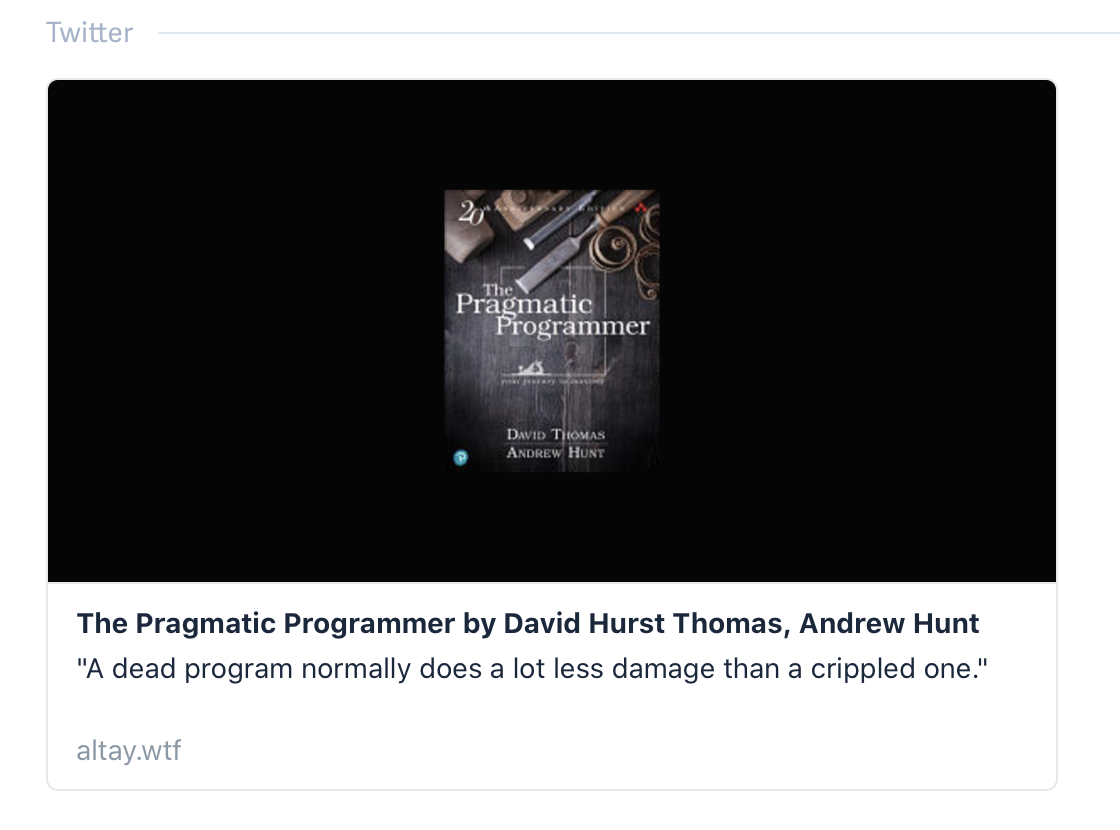
If you like to take notes from the books you read and know a little bit of JavaScript, this may help you.
I've been using Apple Notes, Notion, sticky notes, and paper for my notes. They were unorganized and hard to index when needed. I moved all to Markdown, and started publishing on this website.
Taking notes is the hard part. Once they are in place, making them look pretty is a joyful task to deal with. That's what I did while building the book pages, without spending too much effort on details. It took me half-a-day to make it legit enough to share in this post.
Adding front-matter to Markdown
We need some manual labor to do before we get to the acrobatics.
We can use YAML syntax at the beginning of a Markdown file to define the metadata. There's a library called gray-matter to parse it to JSON so we can use it in the next steps.
--- isbn: '0135957052' date_read: '2020-08-27' oneliner: A dead program normally does a lot less damage than a crippled one. --- ## Chapter 1: A Pragmatic Philosophy ...
import fs from 'fs' import matter from 'gray-matter' type BookNote = { content: string data: { isbn: string date_read: string oneliner: string } } const readMarkdownFile = (filePath: string) => { const file = fs.readFileSync(filePath, 'utf-8') const { data, content } = matter(file) return { data, content } as BookNote }
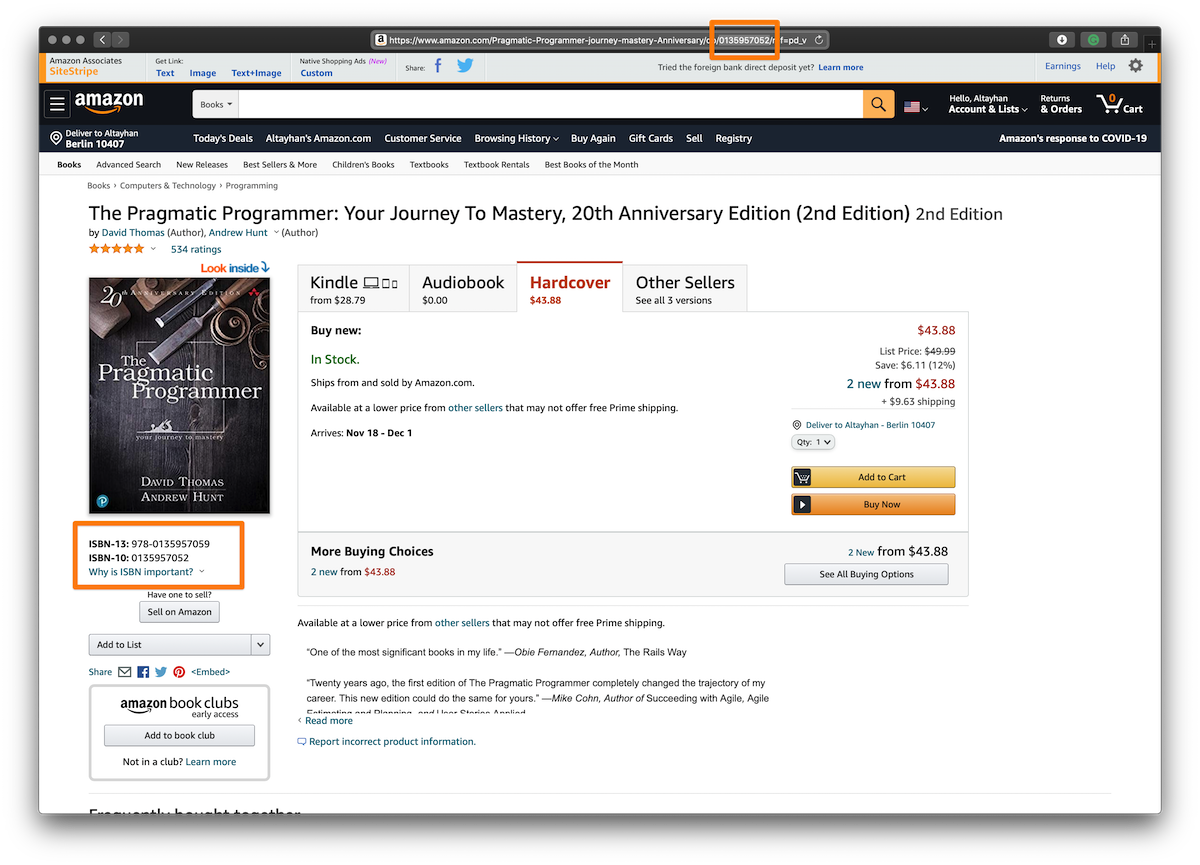
It's easy to retrieve a lot of information and generate specific meta images by using the ISBN. That is the only identifier we need for the rest. Amazon usually uses ISBN-10 as a path parameter for the product pages.
Using Google Books API for metadata
If we only need essential information like title, authors, and cover image, we can proceed with the Google Books API. Not sure if it's a bug or feature, but some endpoints don't need authentication. Obtaining an API key is not that hard as well. We just need to create a Google account and register a new app to use the Books API.
Google Books has a pretty simple query endpoint that we can pass the ISBN and API keys as parameters. Unfortunately, thumbnail images are low-resolution. It looks a bit ugly, but doubling the dimensions during the transformation can be a solution.
type BookData = { isbn: string title: string authors: string[] coverImageURL: string } type GoogleBooksQueryResult = { totalItems: number items: Array<{ volumeInfo: { title: string authors: string[] imageLinks: { thumbnail: string } } }> } const decodeGoogleBooksResponse = (json: GoogleBooksQueryResult): BookData => ({ isbn, title: json.items[0].volumeInfo.title, authors: json.items[0].volumeInfo.authors, coverImageURL: json.items[0].volumeInfo.imageLinks.thumbnail, }) const BASE_URL = `https://www.googleapis.com/books/v1/volumes` const fetchBookMetadata = async (isbn: string): Promise<BookData> => { const url = `${BASE_URL}?q=isbn:${isbn}&key=${GOOGLE_BOOKS_API_KEY}` const response = await fetch(url) const json = await response.json() return decodeGoogleBooksResponse(json) }
Creating a meta image for the Book page
Now that we have the least relevant information to render a book page, we can take some time to prettify the meta tags. Here's how related services render the meta images related to book pages.
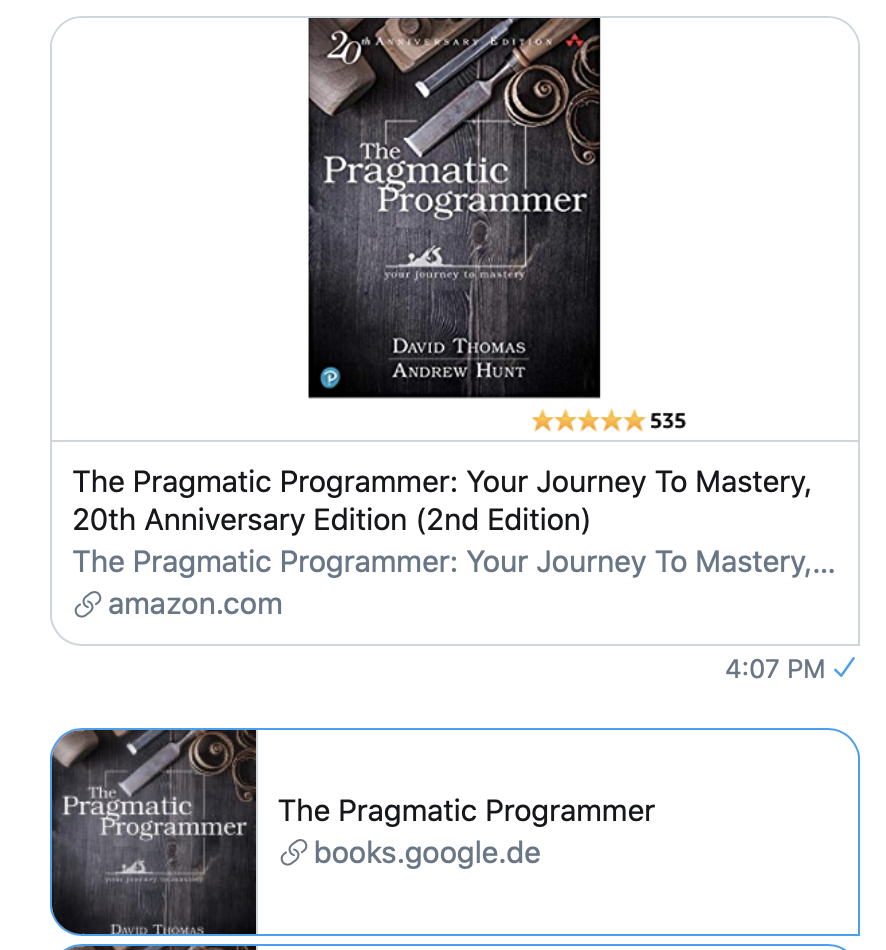
Alright, that is doable with what we have.
In my experience, the easiest way to generate a custom image in the NodeJS context is to use a canvas library. The easiest to use I found is, hold your breath, called canvas. I also use image-size to gather the width and height properties.
Here's the flow:
- Fetch the metadata from Google Books API.
- Fetch the thumbnail image as blob.
- Extract the width and height properties.
- Create a canvas with the size of the OpenGraph image.
- Place the thumbnail in the middle, double the size to make it look bigger.
- Save the generated image to somewhere.
- Return the URL.
import { createCanvas, loadImage } from 'canvas' import fetch from 'node-fetch' import imageSize from 'image-size' import fs from 'fs' type ImageData = { buffer: Buffer width: number height: number } const getImageDataFromBuffer = (buffer: Buffer): ImageData => { const { width, height } = imageSize(buffer) if (!width || !height) { throw new Error('Could not get image data') } return { buffer, width, height } } const getImageData = async (url: string): Promise<ImageData> => { const response = await fetch(url) const buffer = await response.buffer() return getImageDataFromBuffer(buffer) } const META_IMAGE_WIDTH = 1200 const META_IMAGE_HEIGHT = 628 const META_IMAGE_BG_FILL_COLOR = '#050505' const createCanvasForMetaImage = () => { const canvas = createCanvas(META_IMAGE_WIDTH, META_IMAGE_HEIGHT) const context = canvas.getContext('2d') context.fillStyle = META_IMAGE_BG_FILL_COLOR context.fillRect(0, 0, META_IMAGE_WIDTH, META_IMAGE_HEIGHT) return { canvas, context } } const generateMetaImageForBook = (book: BookData) => { const imagePath = `../public/images/${book.isbn}.png` const imageData = await getImageData(book.coverImageURL) const image = await loadImage(imageData.buffer) const coordinates = { x: (META_IMAGE_WIDTH - imageData.Width) / 2, y: (META_IMAGE_HEIGHT - imageData.Height) / 2, } const { canvas, context } = createCanvasForMetaImage() context.drawImage( image, coordinates.x, coordinates.y, imageData.width, imageData.height, ) fs.writeFileSync(imagePath, canvas.toBuffer('image/png')) return imagePath }
Since it's a Next.js app, I prefer to save it to the filesystem. An alternative approach could be uploading to a CDN.
After injecting the meta images to the book pages, metatags.io is a great tool to verify how they look.